2020.09.09
サイトリニューアルの事前調査:全ページリスト作成方法
サイトリニューアルのときに重要なのは「事前調査」です。
簡単に言うと、「全ページ確認」します。
モレ・ムダなく全ページ確認するにはリストが不可欠です。
今回は「全ページリストの作成方法」をご紹介いたします。
目次
全ページリストの作成方法
【1】Website Explorer でデータを取得・Excel に出力する
Website Explorerは、インターネット上で公開されているサイトの情報を取得して階層表示するアプリケーションです。外部リンクやリンクエラーの一覧も出力できます。
Website Explorer (ウェブサイト・エクスプローラ)の詳細情報 : Vector ソフトを探す!
※作者の梅ちゃん堂さんによる開発は終了しており、公式サイトは消滅しています。アプリケーションの使用は自己責任でお願いします。
※リンク追跡でサイト情報を取得するため、リンクで辿ることのできない孤立ページやファイルのデータ、 JavaScript で生成したリンクは収集できません。
▼「Excel に出力」のおすすめ設定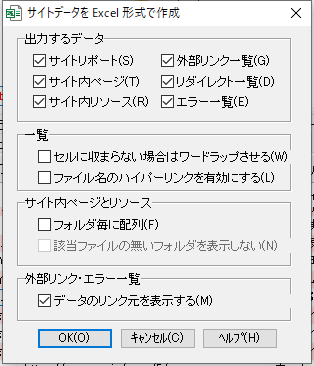
※1「出力するデータ」にある「外部リンク一覧」にチェックを入れると処理が重くなるかもしれないので、特に必要でなければ外しておいてもいいかもしれません。(ぺいじずでは外部リンク一覧にチェックをいれて出力を実行したところ、当該部分にさしかかったときにタスクが停止してWebsiteExplorerが応答してくれなくなりました)
これに関しては様々な要因が考えられますので、必要に応じてチェックをいれてもらえればと思います。
※2「サイト内ページとリソース」にある「フォルダ毎に配列」のチェックを外しておいた方がいいです。チェックがついたままサイトデータを出力するとリスト形式になりません。(ちなみにチェックを入れるとサイトデータがフォルダ単位でまとめられた状態で出力されます)
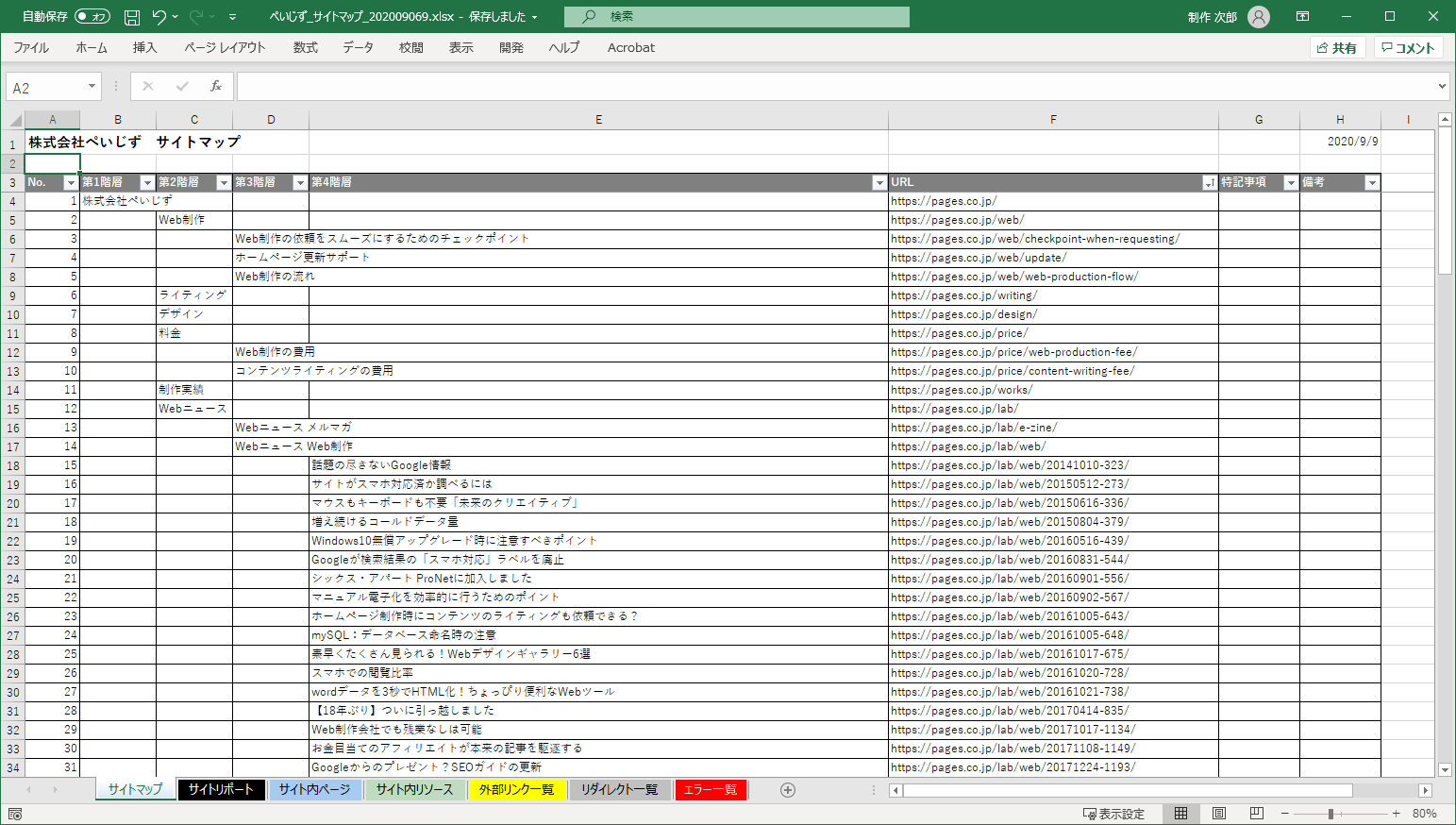
【2】出力したExcelファイルを見やすくする
以下、ダウンロードした Excel ファイルを整形して見やすくする手順をご紹介します。
・「サイト内ページ」タブを複製します。
・1行目の結合見出しを削除します。
・「メタ・ディスクリプション」「メタ・キーワード」「H1 タグ」「更新日」「サイズ」「ファイル」列を削除します。
・1番左に「No.」列を追加します。
・「タイトル」列の共通テキストを削除します。
(例:「記事名 | 会社名」の「 | 会社名」箇所)
・「タイトル」を「第N階層(記事が多そうな階層)」に変更します。
また、適宜前後の列に「第N階層」を追加します。
・「URL」列の右に「特記事項」「備考」列を追加します。
・「URL」列の「index.html」「index.htm」などを削除します。
※index.html、index.hmlを削除する目的はサイトデータの重複を処理するための下準備です。重複のない綺麗な全ページリストを作成するために必要な手順です。
・「URL」列でソートします。
・「URL」列の重複行を削除します。
・サイトメニューに合わせて、行を適宜移動します。
また、階層に合わせて、「第N階層」列を適宜移動します。
・「No.」列に連番を追記します。
・1番上に行を追加し、「案件名」「取得日」などを記述します。
・セル幅や罫線、セル色などを整えます。
Excel の列は適宜変更してください。
「備考」列は特に使用しないですが、フィルターを適用したまま列を挿入追加するのに便利なので、ぜひ作成しましょう。
HTML数が多いときは、新着情報は別シートにしたり、自動生成の一覧ページはまとめたりするとよいでしょう。
列や行の移動は大変なので、社内で共有するだけなら割愛してもよいと思います。
その他Website Explorer使用時の補足事項
その他Website Explorerについての補足事項を下記にまとめましたのでご参照ください。
特定ディレクトリを指定できる
トップページだけでなく、サブディレクトリのURLを指定することで指定したURL以下のみのサイトデータを取得することも可能です。
リンクチェックで使える
外部リンク一覧タブにある「データチェック」をクリックすることでリンクチェックが可能です。
サイトダウンローダーとして使える
取得したサイトデータを丸ごとダウンロードすることが可能です。HTML形式に変換することもできます。
使用後・設定の変更後のデータ残存に注意
データ取得に関する設定はデフォルトのままで特に問題ありません。
もちろんお好みで設定を変えてもOKです。ただし設定を変更すると変更内容が保存されるので、次にサイトデータを取得する際は設定が変わっていることをお忘れなく。
また、WebsiteExplorerを使用すると解析ファイル等(WEBEX.ini、_TempolaryData)が生成され、フォルダ内にデータが残ります。(サイトのキャッシュも残ります)
そのまま次のデータ取得を実行すると、例えばサイトを更新したのにキャッシュが残っていたせいで更新前のデータを取得してしまった、等の問題が起きてしまいます。
そのため、WebsiteExplorerを使用する際は毎回zipから展開してキャッシュも何もないフレッシュな状態で使用することをおすすめしています。
ちなみに、WebsiteExplorerフォルダ内にあるWEBEX.ini、_TempolaryDataを削除することでもフレッシュな状態で使用可能になります。
以上、WebsiteExplorerについての補足でした。
次回は、URLを確認するのに便利なツールをご紹介いたします。